RAPIDS Accelerated User-Defined Functions
This document describes how UDFs can provide a RAPIDS accelerated implementation alongside the CPU implementation, enabling the RAPIDS Accelerator to perform the user-defined operation on the GPU.
Note that there are other potential solutions to performing user-defined operations on the GPU. See the Frequently Asked Questions entry on UDFs for more details.
UDF Obstacles To Query Acceleration
User-defined functions can perform almost arbitrary operations and thus are very difficult to translate automatically into GPU operations. UDFs can prevent potentially expensive portions of a query from being automatically accelerated by the RAPIDS Accelerator due to the inability to perform the custom operation on the GPU.
One possible solution is the UDF providing a GPU implementation compatible with the RAPIDS Accelerator. This implementation can then be invoked by the RAPIDS Accelerator when a corresponding query step using the UDF executes on the GPU.
Limitations of RAPIDS Accelerated UDFs
The RAPIDS Accelerator only supports RAPIDS accelerated forms of the following UDF types:
- Scala UDFs implementing a
Functioninterface and registered viaSparkSession.udf.register - Java UDFs implementing one of the
org.apache.spark.sql.api.java.UDFinterfaces and registered either viaSparkSession.udf.registerorspark.udf.registerJavaFunctionin PySpark - Simple or Generic Hive UDFs
Other forms of Spark UDFs are not supported, such as:
- Scala or Java User-Defined Aggregate Functions
- Hive Aggregate Function (UDAF)
- Hive Tabular Function (UDTF)
- Lambda Functions
Adding GPU Implementations to UDFs
For supported UDFs, the RAPIDS Accelerator will detect a GPU implementation if the UDF class implements the RapidsUDF interface. Unlike the CPU UDF which processes data one row at a time, the GPU version processes a columnar batch of rows. This reduces invocation overhead and enables parallel processing of the data by the GPU.
This interface requires implementing the following method:
ai.rapids.cudf.ColumnVector evaluateColumnar(int numRows, ai.rapids.cudf.ColumnVector... args);
The implementation of evaluateColumnar must return a column with the specified number of rows. All input columns will contain the same number of rows.
Interpreting Inputs
The RAPIDS Accelerator will pass columnar forms of the same inputs for the CPU version of the UDF. For example, if the CPU UDF expects two inputs, a String and an Integer, then the evaluateColumnar method will be invoked with an array of two cudf ColumnVector instances. The first instance will be a column of type STRING and the second a column of type INT32. The two columns will always have the same number of rows, but the UDF implementation must not make any assumptions on the number of input rows.
Scalar Inputs
Passing scalar inputs to a RAPIDS accelerated UDF is supported with limitations. The scalar value will be replicated into a full column before being passed to evaluateColumnar. Therefore the UDF implementation cannot easily detect the difference between a scalar input and a columnar input.
Resource Management for Intermediate Results
GPU memory is a limited resource and can become exhausted when not managed properly. The UDF is responsible for freeing any intermediate GPU results computed during the processing of the UDF. The inputs to the UDF will be closed by the RAPIDS Accelerator, so the UDF only needs to close any intermediate data generated while producing the final result that is returned.
Generating Columnar Output
The evaluateColumnar method must return a ColumnVector of an appropriate cudf type to match the result type of the original UDF. The following table shows the mapping of Spark types to equivalent cudf columnar types.
| Spark Type | RAPIDS cudf Type |
|---|---|
BooleanType | BOOL8 |
ByteType | INT8 |
ShortType | INT16 |
IntegerType | INT32 |
LongType | INT64 |
FloatType | FLOAT32 |
DoubleType | FLOAT64 |
DecimalType | See the decimal types section |
DateType | TIMESTAMP_DAYS |
TimestampType | TIMESTAMP_MICROSECONDS |
StringType | STRING |
NullType | INT8 |
ArrayType | LIST of the underlying element type |
MapType | LIST of STRUCT of the key and value types |
StructType | STRUCT of all the field types |
For example, if the CPU UDF returns the Spark type ArrayType(MapType(StringType, StringType)) then evaluateColumnar must return a column of type LIST(LIST(STRUCT(STRING,STRING))).
Returning Decimal Types
The RAPIDS cudf equivalent type for a Spark DecimalType depends on the precision of the decimal.
DecimalType Precision | RAPIDS cudf Type |
|---|---|
| precision <= 9 digits | DECIMAL32 |
| 9 digits < precision <= 18 digits | DECIMAL64 |
| 18 digits < precision | Unsupported |
Note that RAPIDS cudf decimals use a negative scale relative to Spark DecimalType. For example, Spark DecimalType(precision=11, scale=2) would translate to RAPIDS cudf type DECIMAL64(scale=-2).
RAPIDS Accelerated UDF Examples
Source code for examples of RAPIDS accelerated UDFs is provided in the udf-examples project.
GPU Support for Pandas UDF
NOTE
The GPU support for Pandas UDF is an experimental feature, and may change at any point it time.
GPU support for Pandas UDF is built on Apache Spark’s Pandas UDF(user defined function), and has two features:
-
GPU Assignment(Scheduling) in Python Process: Let the Python process share the same GPU with Spark executor JVM. Without this feature, in a non-isolated environment, some use cases with Pandas UDF (an
independentPython daemon process) can try to use GPUs other than the one we want it to run on. For example, the user could launch a TensorFlow session inside Pandas UDF and the machine contains 8 GPUs. Without this GPU sharing feature, TensorFlow will automatically use all 8 GPUs which will conflict with existing Spark executor JVM processes. -
Increase Speed: Speeds up data transfer between JVM process and Python process.
To enable GPU support for Pandas UDF, you need to configure your Spark job with extra settings.
- Make sure GPU
exclusivemode is disabled. Note that this will not work if you are using exclusive mode to assign GPUs under Spark. To disable exclusive mode, usenvidia-smi -i 0 -c Default # Set GPU 0 to default mode, run as root. -
Currently, the Python files are packed into the RAPIDS Accelerator jar.
On Yarn, you need to add
... --py-files ${SPARK_RAPIDS_PLUGIN_JAR} \On Standalone, you need to add
... --conf spark.executorEnv.PYTHONPATH=${SPARK_RAPIDS_PLUGIN_JAR} \ --py-files ${SPARK_RAPIDS_PLUGIN_JAR} \ -
Enable GPU Assignment(Scheduling) for Pandas UDF.
... --conf spark.rapids.sql.python.gpu.enabled=true \
Please note: every type of Pandas UDF on Spark is run by a specific Spark execution plan. RAPIDS Accelerator has a 1-1 mapping support for each of them.
| Spark Execution Plan | Data Transfer Accelerated | Use Case |
|---|---|---|
| ArrowEvalPythonExec | yes | Series to Series, Iterator of Series to Iterator of Series and Iterator of Multiple Series to Iterator of Series |
| MapInPandasExec | yes | Map |
| WindowInPandasExec | yes | Window |
| FlatMapGroupsInPandasExec | yes | Grouped Map |
| AggregateInPandasExec | yes | Aggregate |
| FlatMapCoGroupsInPandasExec | yes | Co-grouped Map |
Other Configuration
The following configuration settings are also relevant for GPU scheduling for Pandas UDF.
-
Memory efficiency
--conf spark.rapids.python.memory.gpu.pooling.enabled=false \ --conf spark.rapids.python.memory.gpu.allocFraction=0.1 \ --conf spark.rapids.python.memory.gpu.maxAllocFraction= 0.2 \Similar to the RMM pooling for JVM settings like
spark.rapids.memory.gpu.allocFractionandspark.rapids.memory.gpu.maxAllocFractionexcept these specify the GPU pool size for the Python processes. Half of the GPU available memory will be used by default if it is not specified. -
Limit of concurrent Python processes
--conf spark.rapids.python.concurrentPythonWorkers=2 \This parameter limits the total concurrent running Python processes for a Spark executor. It defaults to 0 which means no limit. Note that for certain cases, setting this value too small may result in a hang for your Spark job because a task may contain multiple Pandas UDF(
MapInPandas) instances which result in multiple Python processes. Each process will try to acquire the Python GPU process semaphore. This may result in a deadlock situation because a Spark job will not proceed until all its tasks are finished.For example, in a specific Spark Stage that contains 3 Pandas UDFs, 2 Spark tasks are running and each task launches 3 Python processes while we set this
spark.rapids.python.concurrentPythonWorkersto 4.df_1 = df_0.mapInPandas(udf_1, schema_1) df_2 = df_1.mapInPandas(udf_2, schema_2) df_3 = df_2.mapInPandas(udf_3, schema_3) df_3.explain(True)The RAPIDS Accelerator query explain:
... *Exec <MapInPandasExec> could partially run on GPU *Exec <MapInPandasExec> could partially run on GPU *Exec <MapInPandasExec> could partially run on GPU ...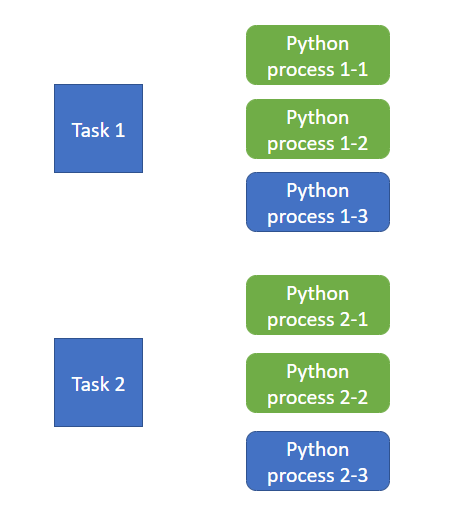
In this case, each Pandas UDF will launch a Python process. At this moment two Python processes in each task(in light green) acquired their semaphore but neither of them are able to proceed because both of them are waiting for their third semaphore to start the task.
Another example is to use
ArrowEvalPythonExec, with the following code:import pyspark.sql.functions as F ... df = df.withColumn("c_1",udf_1(F.col("a"), F.col("b"))) df = df.withColumn('c_2', F.hash(F.col('c_1'))) df = df.withColumn("c_3",udf_2(F.col("c_2"))) ...The physical plan:
+- GpuArrowEvalPython +- ... +- ... +- GpuArrowEvalPythonThis means each Spark task will trigger 2 Python processes. In this case, if we set
spark.rapids.python.concurrentPythonWorkers=2, it will also probably result in a hang as we allow 2 tasks running and each of them spawns 2 Python processes. Let’s say Task_1_Process_1 and Task_2_Process_1 acquired the semaphore, but neither of them are going to proceed becasue both of them are waiting for their second semaphore.
To find details on the above Python configuration settings, please see the RAPIDS Accelerator for Apache Spark Configuration Guide. Search ‘pandas’ for a quick navigation jump.
mapInArrow
mapInArrow is a PySpark API introduced in Spark 3.3.0. The RAPIDS Accelerator supports acceleration for mapInArrow in the same way as Pandas UDF.